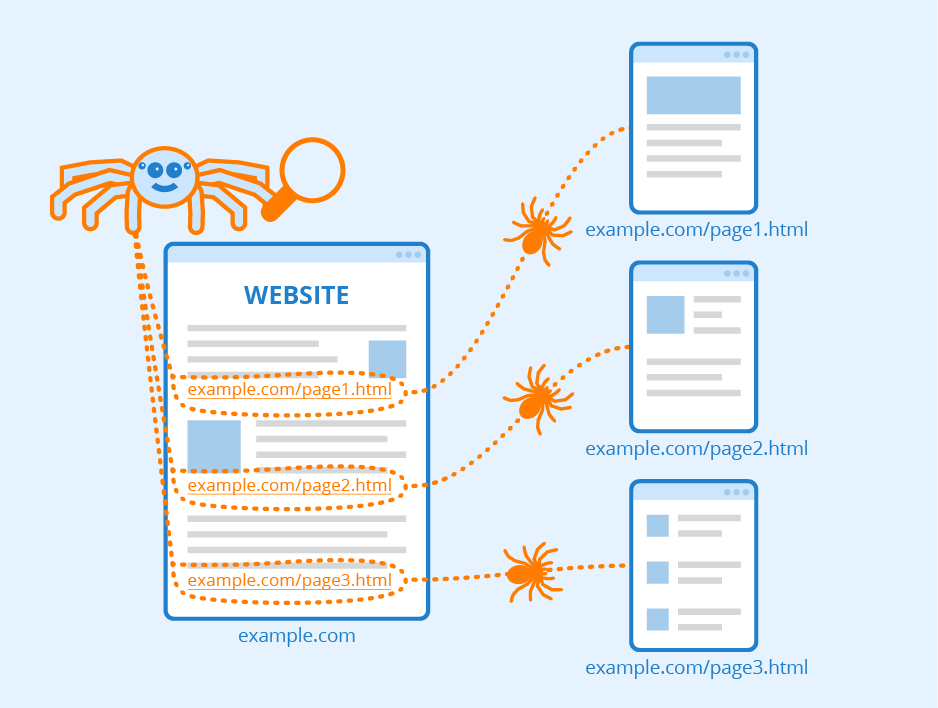
Imagine if I tell you to crawl the entire internet and make a list of all the websites and the pages they contain in a day.
I am sure you would say it is humanly impossible.
I too have no doubt about it. Scouring the entire internet and getting information about all the websites on it in one day is a massive task for any human being.
Search engines understand that too and that is why they send bots, crawlers, or spiders to make the impossible possible. These bots crawl your website along with zillions of others to get information about them.
To get more clarity about what crawling in SEO is and how these crawlers or bots work, here is a guide.
What is crawling in SEO?
In extremely simple terms, crawling is when search engines send to a web page or post to read it. It is the process of discovery where search engines send robots to find new and updated content.
“We start somewhere with some URLs, and then basically follow links from thereon. So we are basically crawling our way through the internet (one) page by page, more or less,” describes Martin Splitt, Google Webmaster Trend Analyst.
The search engine aims to crawl the entire internet quickly and efficiently. But scouring the internet is a huge task as there are innumerable websites and pages.
In 2008, Google crawled 1 trillion pages. In 2013, it jumped up to 30 trillion pages and in 2017 the numbers reached 130 trillion. So, you can imagine that making your site discovered by Google is not a small feat.
Hence, understanding how search engines crawl is the only way to make them notice your site.
Crawling is one of the primary functions of search engines. The other 2 functions are indexing and ranking.
Indexing is storing and organizing content found during crawling. Once your page is indexed it would be running to be displayed as a search result for relevant queries.
The ranking is providing content that would best answer the users’ queries. In short, the most relevant ones will top the list and the least relevant ones will be at the bottom.
What are the different types of crawlers?
Web crawlers, also known as robots, spiders, and ants, are computer programs that visit websites and read their pages to make entries for a search engine’s index.
Here are some of the most popular crawlers –
- GoogleBot
- BingBot
- SlurpBot
- DuckDuckBot
- Sogou Spider
- Facebook external Hit
- AppleBot
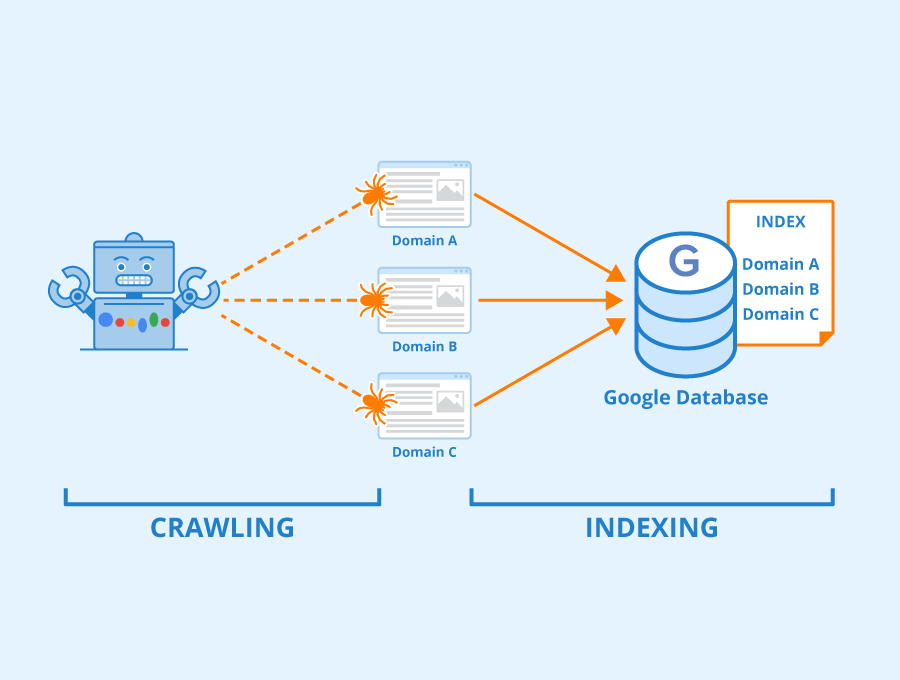
Is there a difference between crawling and indexing?
You might be wondering how Google or any search engine decides which site to crawl.
The answer is simple: there are computer programmes that determine which site to crawl and how many pages to fetch from a site and how often crawl bots should crawl a site.
The crawler starts its work with a list of web addresses and uses the links on these sites to discover other pages. It pays special attention to new sites, changes made in existing sites, and dead links.
Indexing starts after crawling. It is where the ranking process starts after crawlers crawl a website. Indexing is nothing but adding a webpage’s content to a search engine to be considered for the ranking.
Keep your hair down, you do not need to do anything to get your website or webpage indexed. Google crawlers will do the rest of the work. They crawl a page and save a copy of the information on the index server and when a user performs a relevant search query the search engine shows the page.
Hence, without crawling your website will not be indexed and as a result, it won’t appear in search results.
Now that you know what is crawling, let’s delve into what is crawl budget, which I am sure you have heard too many times.
What is a crawl budget?
Now, imagine you are a web crawler and you have the responsibility to crawl all the websites on the internet. How would you crawl? (Choose from the two options given below)
Option A: You would make sure you crawl every single page of a website before moving on to crawl the next website but you may not be able to crawl every website on the internet.
Option B: You allocate a fixed time frame to crawl a website before you move on to the next, thereby making it possible for you to crawl all websites but you may not be able to crawl each website completely.
I am sure you would agree with me that option B sounds like a better option.
Well, Google does the crawling in the same manner. It has a crawl budget and it crawls sticking to the budget.
Simply put, the amount of time and resources that Google invests while crawling a site is generally called the site’s crawl budget.
This means when your crawl budget is exhausted the crawler will stop accessing your site and go ahead with another site.
Your website’s crawl budget depends on the following factors –
- Website’s popularity on the internet.
- Your server’s capabilities.
- The freshness of your content.
- Size of your website will impact the crawl budget. The bigger the site the more the crawl budget.
Can you tell search engines how to crawl your site?
Yes, you can definitely tell search engines how to crawl your site. And doing so will give you a better control over what gets indexed. You can direct Googlebot away from certain pages which you do not want to index.
This might include duplicate URLs, old URLs with thin content, test pages, or special promo codes.
To keep Googlebot away from certain pages you can use a robots.txt file.
What search engines can’t see
Difficult navigation
Many sites keep their navigation in a way that is inaccessible to search engines. And this hinders their ability to get indexed and listed in search engine results.
- If the menu items are not in the HTML, the search engine might fail to read it.
- It can be due to having two different types of navigation for different devices like mobile and desktop.
- Not linking a primary page through your navigation might also hinder search engines from finding it.
Protected pages
If on certain pages, users need to log in, answer survey, or fill in forms, crawlers won’t see those protected pages.
Text is hidden in non-text media
You should avoid using non-text media forms to show text that you want to be indexed. Search engines might fail to get such content. It is better to write text within the <HTML> markup of your website.
How to tell crawlers what to crawl?
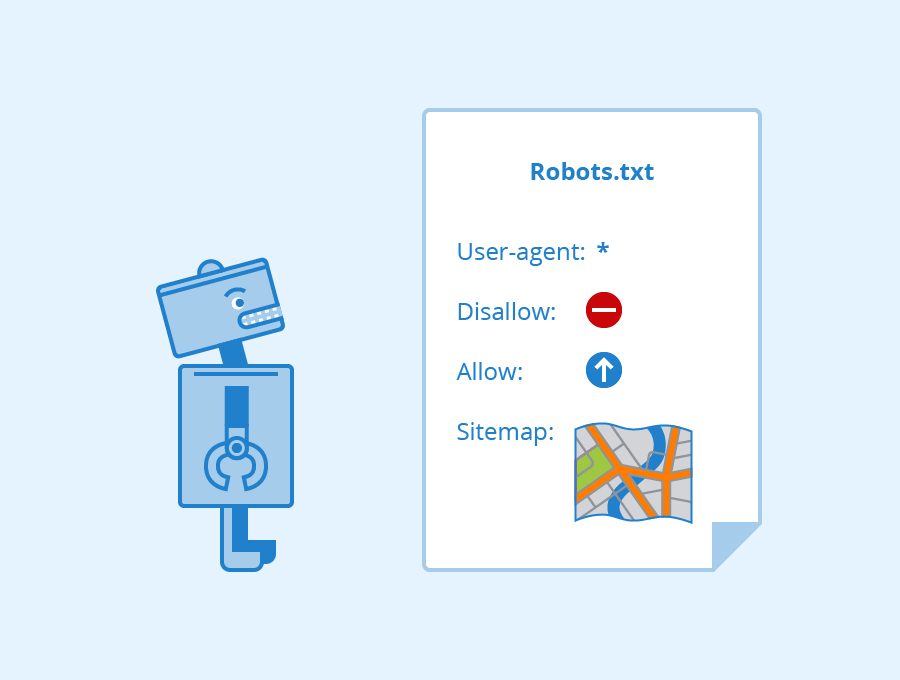
There are many ways to tell crawlers what to crawl. Some of them are –
Robots.txt file
These files are located in the root directory of a site.
This (https://sanjayshenoy.com/robots.txt) is where you will find my robots.txt file. To find yours, use yourdomain.com/robots.txt. You can then suggest which pages in your website need to be crawled.
The crawler will check the robot.txt file and proceed to crawl the site abiding by the suggestions. To have more clarity in robots.txt check our blog.
Utilising site map
The site map of your website will tell Google which pages are important. It might also guide crawlers how often they can be recrawled. Google might find your pages without including them in the site map. But let’s make things simpler.
To check whether a page is in your site map, go to the search console and use the URL inspection tool. You can do the same by going to your site map URL (yourdomain.com/sitemap.xml) and search for the page.
Internal links with no follow tag
Google does not crawl no follow links, hence you should make sure that no internal links to indexable pages have nofollow tag.
Check for Orphan pages
Orphaned pages do not have internal links from other pages. As Google crawls and discovers new content, the bots fail to discover such pages. You can check whether your site has orphaned pages or not using Ahref’s Site Audit.
Conclusion
The way Google perceives the content of webpages, the connection between the pages, what images convey and words actually mean is a wonderful feat and a marvel of technical excellence. Understanding the crawling process is extremely important for you as a website owner.
I hope the information I have provided above has helped you in understanding this magical process.
Comment below to let me know whether the tips and tricks shared here helped you reach your SEO goals.
FAQs
How can I increase crawling on my website?
Here are some tips to increase crawling on your site:
1. Increase page loading speed
2. Submit your site map to Google
3. Perform a site audit
4. Update Robots.txt file
5. Check for low quality and duplicate content
6. Update content regularly
7. Build a strong internal link structure
How do you identify a crawler?
A crawler has the following characteristics –
a) A large number of URL visits.
b) High HTTP request rate and typically done in parallel.
c) More requests for a certain type of file over others.
You can check out A Hybrid Approach to Detect Malicious Web Crawlers by Hillstonenet for more details.
What are the types of crawlers?
There are three main types of web crawlers –
– Inhouse web crawlers
– Commercial web crawlers
– Open- source web crawlers

