Imagine getting a new electronic device without a user manual.
You will eventually figure out how to use it right through trial and error. But don’t you think it would save you time and avoid the error part if you had a book of instructions that tells you what to do and avoid?
It is the same for search engines.
When they find your website to crawl, they will go through the whole site content by content and eventually find the valuable parts of it. But give them an instruction manual, they can avoid the content that is unnecessary for the public and hit the most valuable sections directly.
This article is about the user manual for a search engine in its own language.
It is called robots.txt!
What is robots.txt in SEO?
A robots.txt file is a text file that tells the search engine where it can go and cannot go on a website.
It is also called the robots exclusion protocol or standard. It is designed to help the search engine like an instruction manual and it is the first place the search engine goes to when crawling a website.
Where to find the robots.txt file on a website?
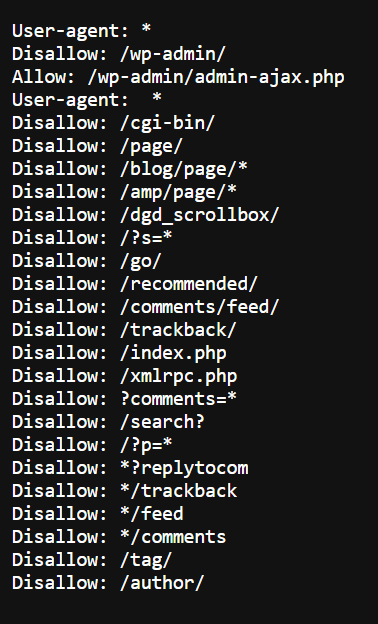
You can get the robots.txt file of any website by writing domainname.com/robots.txt in the address bar.
When you do, you may find three things:
- A coded text on the page
- An empty file.
- A 404 error
You do not want an empty file or a 404 error. The text file on my website looks like the image below.
Do you need a robots.txt file for a website?
Honestly, you don’t.
Search engines would crawl and index your website as they normally would even without it. Especially if the website is on a smaller scale. When I say the smaller scale, I am talking 500 to 1000 pages.
Then why am I taking the trouble to write this article?
Believe me, I have a purpose.
Robots.txt file may be designed for the search engine, but it gives you more control over what is being crawled on your website because it tells the search engine what to crawl and what not to crawl.
First, let me familiarize you with some crawl terminology.
Crawl budget
It is the amount of time and resources that a search engine devotes to crawling. It is determined by your website’s popularity on the internet, your server’s capabilities, the freshness of the content, and the number of pages on your website.
Crawl rate limit
It is the maximum fetching rate for a given site. Crawling is the main job of the Google bot while making sure it is not degrading user experience on a given site.
If a website is responding quickly, the crawl limit goes up. If the response is slow or there are server errors, the crawl rate goes down.
The limit can be set to reduce in the Google Search Console.
Crawl demand
Crawl demand is the popularity of your website. Google bots crawl popular pages and keep them fresh for indexing.
The number of URLs the bots can and want to crawl is a combination of the crawl rate limit and crawl demand for the crawl budget.
You want to help Google or any search engine to make the best use of the crawl budget on your website, while you would also want it to be crawling your most valuable web pages.
Do you know who could prevent this from happening?
Low-value-add URLs, that’s who!
According to Google, these are:

These pages drain the server resources and would cause a significant delay in finding valuable content on a website. You would not want that, would you?
This is where the robots.txt file comes into play. You can tell the Google bots and any other search engine bots what pages can be avoided. Using the file rightly can be very useful in the SEO context.
I told you I was getting somewhere with this.
The benefits of using a robots.txt file are:
1) You can hide certain files and subdomains from the public: You don’t want all your web pages to be indexed.
For example, your login page or a page that is not fully developed, which is not meant for the public eye. Use robots.txt to disallow the crawlers from the pages.
2) You can avoid crawling duplicate content.
3) You can optimize the crawl budget: You can use your Google Search Console to see which pages of the website are indexed.
If you are having trouble indexing your important pages due to a crawling budget shortage, you can block the unimportant pages on robots.txt. Googlebot can purely spend the crawl budget on the pages of value.
4) You can also prevent the indexing of resources: You can also specifically prevent some pages from getting indexed by using something called the meta tag.
5) It can help manage server overload by using crawl-delay.
Eg: “Crawl-delay: 7” slows the crawl by 7 milliseconds.
6) You can specify the location of the sitemap on your website.
How to create and add robots.txt in WordPress?

For most SEO-related functions, I depend on and highly recommend the Rank Math Pro Plugin, which is very handy and easy to use.
The General Settings in the Rank Math Dashboard gives you the robots.txt text editor where you can add and modify the robots.txt file like what you saw in the image of my robots.txt file.
You can pretty much write the same thing for yourself.
Google gives a helpful guide to creating a robots.txt file and details on how to update it, and how Google interprets the file. You can give it a read for an insightful understanding.
The components of a robots.txt file
The robots.txt file consists of different blocks on directives. It begins with a user agent and a set of rules set out for those user agents.
User-agent
The user-agent commands are used to direct a code to target bots. They may be Google bots, bing bots, etc If you want to target only Google bots.
Then the directive starts with:
User-agent: Googlebot
Other examples of user agents are:
User-agent: Bingbot
User-agent: Googlebot-Image
User-agent: Googlebot-Mobile
User-agent: Googlebot-News
User-agent: msnbot
These are case-sensitive, so you need to be careful if you are writing them yourself.
Wildcard User-agent: An * symbol (asterisk) applies to all of the bots that exist and visit the websites. So if you want the directives to apply to all you can use them.
User-agent: *
Disallow
You use this to indicate to the search engine that a page should not be crawled or it should not access certain pages on a website.
Examples of different ways this command can be used are:
a) Prevent access to a specific folder:
User-agent: *
Disallow: /
The “/” (slash) after the Disallow: instructs the bot to not visit any of the pages on the website. In case your website is under development and you do not want search engines to crawl yet, you can block them using the above command.
b) If you are going specific, say the admin page of a blog on WordPress, then the following command is used:
User-agent: *
Disallow: /wp-admin/
- Disallowing only Googlebot:
User-agent: Googlebot
Disallow: /wp-admin/
- You can block file types
User-agent: *
Disallow: *.pdf$
The $ symbol (dollar) denotes the end of the URL.
Allow
You use this to direct a bot to access and crawl a page. You can override the Disallow directive by adding commands to crawl specific pages.
Sitemap
A sitemap to your website helps the search engine understand how to crawl and find pages on your website. You can include your sitemap in your file to make it easier for the crawlers to locate your sitemap.
This step is not necessary if you are directly submitting your sitemap to the search engine’s webmaster tools like Google Search Console.
The command to add this directive is:
sitemap: https://yourwebsite.com/sitemap.xml
Crawl Delay
As I have already mentioned above in the benefits of robots.txt file, you can use the crawl delay common to slow down a crawler so that your server is not overtaxed.
This may not be productive to use if you have a large website, as it would decrease the number of URLs crawled per day.
Also, Google does not support this command, and you may have to use other methods for the purpose.
Best practices for robots.txt file:
- Ensure that the important pages and content of your website are not blocked.
- Some search engines use more than one user agent. For example, Google bot for organic search is different from those for image search. You can use them to refine crawling on your content.
- See that each directive is in a new line, or it could confuse the search engine.
- Use the “$” symbol to indicate the end of a URL. It is used while writing file names.
- Ensure that each user-agent is used only once to keep it simple and easy.
- Like any code, you can add comments to the robots.txt file so that anyone accessing the file will know what the directives are for.
Comments in robots.txt start with “#”. Any content after the hash symbol will be ignored by the crawler.
Auditing the robots.txt file for errors

The robots.txt file can be checked with the Google Search Console in the Coverage report. You can paste the URL into the Search Console’s URL inspection tool. The result would indicate that the URL is not available and that it is blocked by robots.txt.
You can check which of the directives is blocking the content using Google’s robots.txt tester.
Conclusion
The robots.txt file can be considered among the simplest of files on a website. But simple does not necessarily mean easy. A single error in code can make things awry. It could happen to the best of us.
But done right, it is an effective way to control the crawling on your website and it is good for SEO.
If you have any questions you can leave them in the comments or ping me on LinkedIn.

